
一,索引类型
最常见的索引数据结构是B-Tree索引,按照顺序存储数据,所以mysql可以用来做order by和group by操作,应该数据是有序的,所以b-tree也就会将相关的列值都存储在一起。最后因为索引中存储实际的列值,某些查询只使用索引就可以完成全部查询。
单列索引
单一的一列索引
多列索引
如图,一个包含三列值的普通索引树
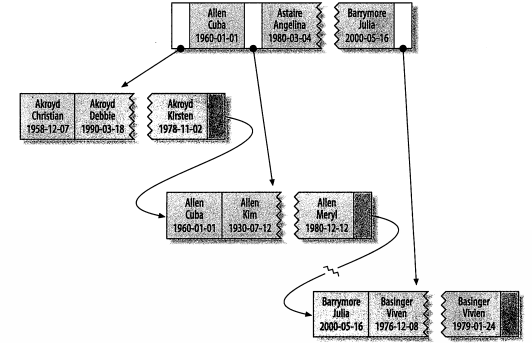
聚簇索引
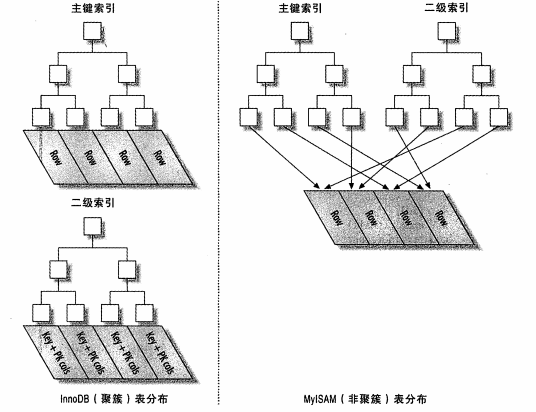
不是一种单独的索引类型,而是一种数据存储方式,innoDB的聚簇索引实际上在同一结构中保存了B-Tree索引和数据行,当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中,不是所有的存储引擎都支持聚簇索引。
聚簇索引和非聚簇索引对比图:
覆盖索引
如果一个索引包含或说覆盖所有需要查询的字段的值,成为覆盖索引
二,如何正确的使用索引?
索引依据
1、依据where查询条件建立索引
eg:select a,b from tb_test where c = ?;idx_c(c) ->正确select a,b from tb_test where c = ? and b = ?idx_cd(c,d) ->正确
2、根据排序order by ,group by , distinct 字段添加索引
eg:select * from tb_test order by a;select a,count(*) from tb_test group by a;idx_a(a) ->正确select * from tb_test order by a,b;idx_a_b(a,b) ->正确select * from tb_test order where c = ? by a;idx_c_a(c,a) ->正确
索引使用-最左前缀原理
例如,以表user中的a,b,c三个列建立联合索引
① 全列匹配: select * from user where a = ? and b =? and c = ?;
使用建立索引的三个列的值,精确使用到具体的索引,即使顺序不同mysql查询优化器会自动调整where语句的顺序(而不是innodb),使之适应索引结构
② 最左前缀匹配: select * from user where a = ? and b =? ;
没有提供完全的列值,索引是从左起进行连续匹配的,因此也能够使用利用a,b,c三列建立起来的索引。
③ 使用索引精确匹配,中间某个条件未提供。Select * from user where a = ? and c =? ;
虽然a和c都在索引列中,但是因为b不存在,所以无法匹配最左前缀的连接。
解决办法:1,如果有大量的查询通过这种方式进行,可以考虑在a和c列上建立一个联合索引。2,通过填坑的方式,即如果b列上的值不多的话(例如枚举,或者简单的bit类型),通过将sql优化成 select * from user where a = ? and b in(?,?,?……) and c = ? 的方式能够提升一部分的性能。
④ 查询没有使用到索引第一列 select * from user where b = ? and c = ?;
这种情况是不符合最左前缀的,无法使用该索引。
⑤ 匹配字符串前缀情况 select * from user where a = ? and b= ? and c like ‘abc%’;
这种情况符合最左前缀,可以使用索引,但如果通配符("_" "%"等)不是出现在末尾,则无法使用。
⑥ 范围查询 select * from user where a > ? and b = ? and c = ?;
这种情况能够使用索引,但是b和c列的索引无法使用到,如果范围查询不是最左前缀或者查询条件中有两个范围列则无法使用。
idx_ab(a,b)为例:
能使用上述索引进行排序的操作是:
order by a;a = 3 order by b;order by a,b;order by a desc ,b desc;a > 5 order by a;
不能使用索引帮助排序的查询
order by b; #没有使用到联合索引的第一个字段a > 5 order by b; #一旦前缀操作是一个range而非=操作,那么就无法利用到索引,这里 a>5无法利用索引,二联合索引的第一个字段未利用,因此 order by b也无法利用索引查询a in (1,3) order by b; #in里面的值没有建立索引,因此无法利用索引,a未用因此order by b也无法使用order by a asc, b desc; #这里order by a esc是利用了索引,但是b desc未利用到,因为b要和a排序方式一致才可利用到索引
⑦ 条件中带有函数或者表达式select * from user where a = ? and b = ? and left(c,2) = ‘ba’
虽然和c like ‘ba%’;达到的效果是一致的,但是由于使用了函数,因此无法使用索引。
对于使用了表达式的sql,例如 select * from user where a = ? and b = ? and c -1 =?;无法使用索引。
⑧ 字段类型不匹配,可能会导致无法使用索引 a int(11) ,idx_a(a)
where a = '123' ->错误,可能导致未知的错误,这个跟编码有关系
where a = 123 ->正确
三,哪些字段适合创建索引?
1、字段值的重复程度
如身份证号码基本上不可能重复,因此选择性非常好,而人的名字重复性较低,选择性也不错, 性别(男/女)选择性较差,重复度非常高
2、选择性很差的字段通常不适合创建索引,但也有例外
如:男女比例相仿的表中,性别不适合创建单列索引,如果走索引不如走全表扫描, 因为走索引的I/O开销更大 但如果男女比例极度不平衡,要查询的又是少数方,如:理工学校、IT公司等可以考虑使用索引
3、联合索引中选择性好的字段应该排在前面
select * from tab_a where gender=? and name=?idx_name_gender(name,gender) ->正确
4、联合索引可以为单列、复列查询提供帮助
idx_smp(a,b,c)where a=?; ->正确where a=? and b=?; ->正确where a=? and c=?; ->正确 (注:需要MySQL5.6版本以上;在5.5及以前版本,可以对a字段进行索引扫描,但c字段不行 )where a=? and b=? and c=? ->正确
5、合理创建联合索引,避免冗余
(a),(a,b),(a,b,c) ->不可取(a,b,c) ->正确,可以覆盖前两个
6,合理使用覆盖索引
对于最核心的SQL,我们可以考虑使用索引覆盖,查询用户名这种操作频率非常高,而索引里面又存储了字段的值,查询时,name字段的值直接在索引中返回,而不需要回表。
覆盖索引覆盖就是将你要查询的字段和条件字段一起建立联合索引,这样的好处是不需要回表获取name字段,IO最小,速度块
select name from tb_user where userid=?key idx_uid_name(userid,name) ->覆盖索引扫描